はじめに
DFTを使った巡回畳み込み積分の性質をもう少し詳しく調べ、具体的な高速化のアイディアを紹介します。
実験
単純なステップ信号に対して差分フィルタ的なカーネルを畳み込む実験をしてみます。
畳み込み方法は、DFTによる方法、numpy.convolveのfullとvalidです。
import numpy
import scipy.fftpack
import matplotlib.pyplot as plt
def __convolve_by_dft(target, kernel):
fft = scipy.fftpack.fft
ifft = scipy.fftpack.ifft
convolved = numpy.real(ifft(fft(target) * fft(kernel)))
return convolved
def __single_plot(values, label_name, y_lower, y_upper):
plt.plot(values, label=label_name, marker="+")
plt.ylim(y_lower, y_upper)
plt.legend()
plt.show()
plt.close()
if __name__ == "__main__":
target = numpy.zeros(16)
for i in range(0, 16, 8):
target[i:i+8] = i // 8
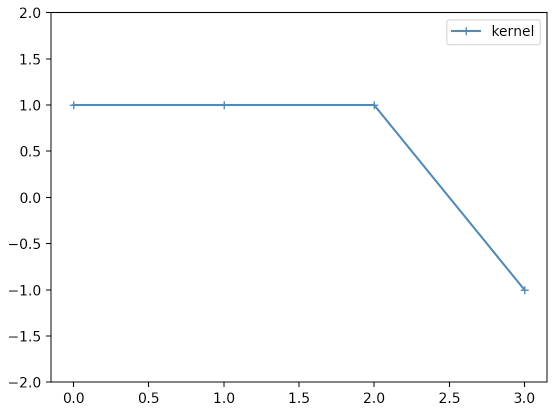
kernel = numpy.array([1,1,1,-1])
dft_convolved = __convolve_by_dft(target, numpy.r_[kernel, numpy.zeros(12)])
numpy_full_convolved = numpy.convolve(target, kernel, mode="full")
cyclic_target = numpy.r_[target[-(len(kernel) - 1):], target]
numpy_valid_convolved = numpy.convolve(cyclic_target, kernel, mode="valid")
__single_plot(target, "target", -2, 2)
__single_plot(kernel, "kernel", -2, 2)
plt.plot(target, label="target", marker="v")
plt.plot(dft_convolved, label="by DFT", marker="o")
plt.plot(numpy_full_convolved[:16], label="by Numpy(Full)", marker="x")
plt.plot(numpy_valid_convolved[:16], label="by Numpy(Valid)", marker="+")
plt.legend()
plt.show()
exit()
ステップ信号です。
フィルタカーネルです。
各手法による畳み込み積分の結果です。

考察
numpy.convolveのフィルタカーネルの仕様
numpy.convolveに指定したフィルタカーネルは、配列要素0が時刻0、配列要素1が時刻-1を表しています。そのため、指定したフィルタカーネルは配列の逆順に畳み込まれます。
ステップ信号のエッジ部分で畳み込みの結果が負値になっていない事からも、フィルタカーネル配列が逆順に畳み込まれている事がわかります。
DFTによる畳み込みとfullモードのnumpy.convolveの結果の差
DFTによる畳み込みと、fullモードのnumpy.convolveの結果が微妙に異なります。
fullモードのnumpy.convolveは、フィルタカーネルと対象信号のそれぞれ端から端までを畳み込みます。足りない部分については0値を埋めて処理します。信号長Mに対してフィルタカーネル長Nで畳み込むと、結果はM+N-1の要素数になります。対象信号の前後にN-1の長さ分の0値をそれぞれ追加して処理します。そのため、同様の0値連結操作を行った対象信号に対するvalidモードのnumpy.convolveの結果と同じ結果になります。
今回の実験例ではフィルタカーネル長が4なので、対象信号の先頭に0値が3要素分自動で追加され、[0,0,0,0]と[-1,1,1,1]の内積を計算した結果になっています。つまり0です。
しばらく0値の結果が続いた後、エッジ部分にフィルタカーネルが差し掛かり、[0,0,0,1]と[-1,1,1,1]との内積計算により、結果が1となります。そこからさらに処理を進めていった結果は以下の通りです。
- $[0,0,1,1]$と$[-1,1,1,1]$との内積計算により結果は$2$
- $[0,1,1,1]$と$[-1,1,1,1]$との内積計算により結果は$3$
- $[1,1,1,1]$と$[-1,1,1,1]$との内積計算により結果は$2$
最終的には、フィルタカーネル長をNとした場合にN-1分だけはみ出して内積計算します。今回の実験例ではN=3のため、末尾に0値を3要素分連結し、[1,0,0,0]と[-1,1,1,1]との内積計算を行い、結果は-1となります。末尾から遡った計算結果は以下の通りです。
- 末尾-0の要素の計算結果は[1,0,0,0]と[-1,1,1,1]との内積計算により-1
- 末尾-1の要素の計算結果は[1,1,0,0]と[-1,1,1,1]との内積計算により0
- 末尾-2の要素の計算結果は[1,1,1,0]と[-1,1,1,1]との内積計算により1
- 末尾-3の要素の計算結果は[1,1,1,1]と[-1,1,1,1]との内積計算により2
これらの結果とDFTによる畳み込みの結果を比べると、先頭3要素の結果が異なる点と、fullモードのnumpy.convolveは末尾3要素分余計に結果が出てきています。
対象信号長をM、フィルタカーネル長をNとすると、DFTによる畳み込みの結果との一致範囲は要素インデックスをゼロオリジンとするとN \sim M-1のM-N + 1要素、今回の実験ではM=16、N=4なので13要素が一致します。
DFTによる畳み込みとvalidモードのnumpy.convolveの結果の比較
DFTによる畳み込みとfullモードによるnumpy.convolveの結果は、先頭N-1要素が異なるのでした。それでは、DFTによる畳み込みでは、先頭N-1要素はどのように算出された値で埋められているのでしょうか?
DFTによる畳み込みは巡回畳み込み積分でした。そのため、対象信号の末尾N-1要素分を先頭に連結してからvalidモードのnumpy.convolveで畳み込みを計算します。
そうすると、先頭N-1の部分についてもDFTの畳み込みの結果と一致します。フィルタカーネルがはみ出す領域を、対象信号の巡回によって作り出して畳み込んだ結果が、DFTによる畳み込みの結果という事になります。
信号の任意長切り出しとゼロ値連結
DFTを使った畳み込み積分の高速化の方法を、overlap-save法と呼ぶようです。前述の通り、DFTによる畳み込み積分の結果の先頭N-1の要素は巡回部分なので使えません。よって、この使えない部分を手前のフレームで算出する事にします。そうなると、フレーム切り出しをオーバーラップして行う事になります。先頭N-1分だけ使えないので、フレーム間のオーバーラップはN-1要素分です。
本気で高速化するのであれば、SIMDアラインメントやキャッシュラインサイズ、また、DFTをFFT高速化する場合は2のべき乗である必要などを考慮して、N-1が高速化に都合の良い値になるようにフィルタカーネル長Nを決める必要があります。しかし、これを素直に実装すると、FIRフィルタの設計に制限が生じてしまいます。
そこで、正しく計算できている部分も余分に捨ててしまい、手前フレームの結果を使ってしまおうと割り切れば、実際のFIRフィルタに対して末尾に0値を連結して都合の良い長さにしてしまっても構いません。
ゼロ値と内積
余談になりますが、誤解を恐れずに言えばベクトル成分中の0値は内積の結果に影響を与えない成分だと言えます。そのため、内積や行列積を高速に計算するために、都合の良い次元数になるように0値を挿入するという計算テクニックがあります。
おわりに
今回はさらに一歩踏み込んで畳み込み積分をDFTで高速化する方法について実験を通して確認してみました。
実装にあたっては、オーバーラップサイズやフィルタカーネル長をどのように設計すれば良いか、世の中に情報が出回っているので、それらを参考にすると良いです。
基本的な考え方は本記事でも紹介した通りなので、まずは自分で試行錯誤してみるのも勉強になると思います。